Why This is Better Than Traditional Databases
A dive into Kafka for enterprise solutions

Introduction
Applications have used traditional databases for a long time with evolutions including NoSQL and big data but are less applicable in today’s modern applications. Traditional databases are monolithic and require human-computer interaction where the database sits passively unless triggered by a query. Modern applications are entirely automated and streamlined following an event streaming process where the data is active and is triggered by events creating a chain of processes fulfilling a business need.
 In 2010 LinkedIn developed Kafka, an open-source distributed event streaming platform that captures data in real-time from databases, sensors, mobile devices, and cloud services for manipulating, processing, reacting to event streams, and routing for a continuous flow of data.
Currently, multiple companies are using Kafka including Uber, Netflix, and Slack to fulfill their business needs.
In 2010 LinkedIn developed Kafka, an open-source distributed event streaming platform that captures data in real-time from databases, sensors, mobile devices, and cloud services for manipulating, processing, reacting to event streams, and routing for a continuous flow of data.
Currently, multiple companies are using Kafka including Uber, Netflix, and Slack to fulfill their business needs.
What are the uses of Kafka
Kafka’s main uses are to read, write, store, and process streams of events reliably for as long as you want and as they occur. A few great benefits include speed, fault tolerance via backup servers and scalability due to data being spread across partitions. Some real-world examples include monitoring vehicles, routing, and processing payments at Uber, Lyft, and Airbnb. Other applications of event streaming include collecting and immediately reacting to customer interactions and orders in the retail, hotel, and travel industries. Kafka can be deployed on virtual machines, containers, the cloud and even hardware making it versatile and elastic.

How does Kafka work
 Kafka is an exceptional microservices tool that works via a distributed system of multiple components spread across multiple computers on a network using server and client communication over TCP. It runs on sets of connected computers (clusters) of several servers through multiple datacenters or cloud regions. Each of these clusters have at least 3 brokers that are simply a Kafka server and runs an instance of the Kafka application that acts as an intermediary between applications sending messages (data) and applications receiving messages leaving no direct communication between sender and receiver.
Kafka is an exceptional microservices tool that works via a distributed system of multiple components spread across multiple computers on a network using server and client communication over TCP. It runs on sets of connected computers (clusters) of several servers through multiple datacenters or cloud regions. Each of these clusters have at least 3 brokers that are simply a Kafka server and runs an instance of the Kafka application that acts as an intermediary between applications sending messages (data) and applications receiving messages leaving no direct communication between sender and receiver.
Producers
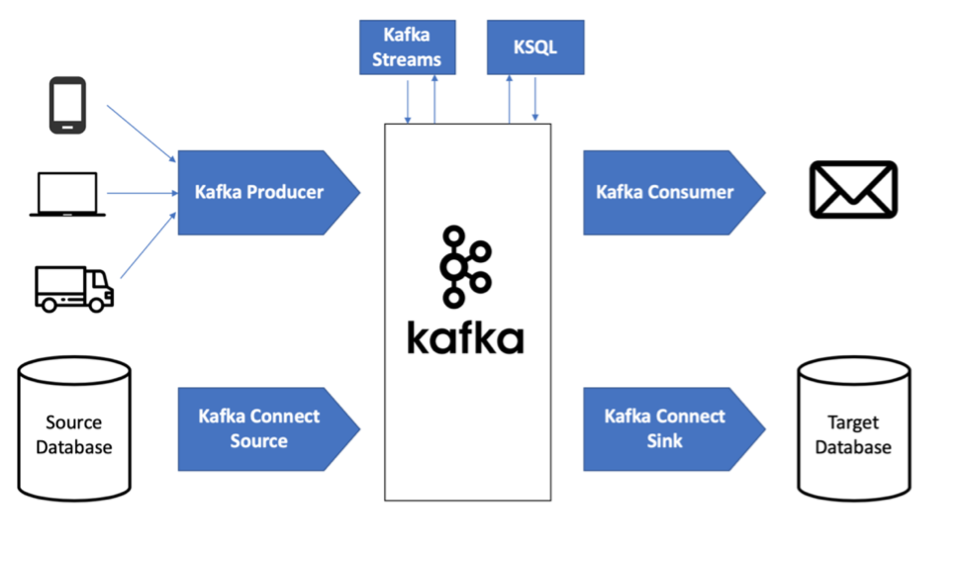 The producer is an application that sends messages to a broker. These messages are sent in batches to increase efficiency in reducing the number of unnecessary networks and are serialized before it is sent.
The producer is an application that sends messages to a broker. These messages are sent in batches to increase efficiency in reducing the number of unnecessary networks and are serialized before it is sent.
Consumers
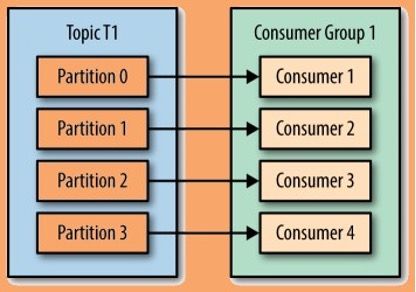 The consumer receives messages from the broker. It does not communicate with the producer directly. Similar to how the producer must serialize messages before sending it, the consumer must deserialize the messages. Consumers can consume multiple topics at once and can also split a topic into multiple partitions where multiple consumers work together to each read from a single partition.
The consumer receives messages from the broker. It does not communicate with the producer directly. Similar to how the producer must serialize messages before sending it, the consumer must deserialize the messages. Consumers can consume multiple topics at once and can also split a topic into multiple partitions where multiple consumers work together to each read from a single partition.
What is Avro
Avro helps serialize the data before sending it to the brokers. In Kafka, Avro can create a schema from a Java class and helps with the data exchange between programming languages, systems, and processing frameworks. This is useful since Avro provides direct mapping to and from JSON, is fast, compact, and is accompanied by a schema.
Learn more
This article has just given a very brief introduction to a higher level understanding of Kafka. To learn more, visit the official Kafka documentation.


